
.
What. A. Year. Thank you to all of the amazing thinkers who generously shared their writing with us during rough waters worldwide. During those times when our work feels like we’re screaming underwater, it’s especially important that we’re still out here making waves. A special shout out in gratitude to our readers, who are listening even harder during our 15th year, and rocking the boat along with us into 2025. –JS, Ed-in-Chief
Here, beginning with number 10, are our Top 10 posts released in 2024 (as of 12/19/24)!
—
A Conversation by Todd Craig and LeBrandon Smith

What is it? The braids?–Kendrick Lamar, “Euphoria”
After a much-anticipated wait, Kendrick dropped “Euphoria.” It not only stopped Hip Hop culture in its tracks, but it allowed all spectators to realize this was gearing up to be an epic battle. The song starts with the backwards Richard Pryor sample from the iconic film The Wiz. For those unfamiliar, The Wiz is a film adaptation of The Wizard of Oz featuring an all-Black star-studded cast, including Diana Ross and Michael Jackson. Richard Pryor played the role of the Wizard. When the characters realize the Wizard is a fraud, he says, “Everything they say about me is true”; this is the sample Kendrick uses, grounding himself in 1970s Black culture and situating where he plans to go in his writing.
[Click here to read more]
—
A Conversation by Todd Craig and LeBrandon Smith
“By now, it’s safe to say very few people have not caught wind of the biggest Hip-Hop battle of the 21st century: the clash between Kendrick Lamar and Drake. Whether you’ve seen the videos, the memes or even smacked a bunch of owls around playing the video game, this battle grew beyond Hip Hop, with various facets of global popular culture tapped in, counting down minutes for responses and getting whiplash with the speed of song drops. There are multiple ways to approach this event. We’ve seen inciteful arguments about how these two young Black males at the pinnacle of success are tearing one another down. We also acknowledge Hip Hop’s long legacy of battling; the culture has always been a ‘competitive sport’ that includes ‘lyrical sparring.'”
[Click here to read more]
—
(8).Technologies of Communal Listening: Resonance at the Museum of Contemporary Art Chicago
By Harry Burson

“In both sound studies and the sonic arts, the concept of ‘resonance‘ has increasingly played a central role in attuning listeners to the politics of sound. The term itself is borrowed from acoustics, where resonance simply refers to the transfer of energy between two neighboring objects. For example, plucking a note on one guitar string will cause the other strings to vibrate at a similar frequency. When someone or something makes a sound, everything in the immediate environs—objects, people, the room itself—will respond with sympathetic vibrations. Simply put, in acoustics, resonance describes a sonic connection between sounding objects and their environment. In the arts, the concept of resonance emphasizes the situated existence of sound as a transformative encounter between bodies in a particular time and place. Resonance has become a key term to think through how sound creates a listening community, a transitory assemblage whose reverberations may be felt beyond a single moment of encounter.
For its recent performance series, simply called Resonance, the Museum of Contemporary Art Chicago drew on this generative concept by bringing together four artists who explore sound as an “introspective force for greater understanding, compassion, and change.” Curated by Tara Aisha Willis and Laura Paige Kyber, the series builds on theories of resonance as an affective relationship between sounding bodies developed by writers and artists like Sonia Louis Davis, Karen Christopher, and Birgit Abels. . .”
[Click here to read more]
——
(7). Sonic Homes: The Sonic/Racial Intimacy of Black and Brown Banda Music in Southern California
by Sara Veronica Hinojos and Alex Mireles

“Sarah La Morena (Sarah the Black woman), or Sarah Palafox, was adopted and raised by a Mexican family in Mexico. At the age of five, she moved to Riverside, California, a predominantly Mexican city an hour east of Compton. Palafox started singing as a way to express the racism she faced as a child in Southern California, feeling caught between her Black appearance and her Mexican sound. She found her voice in church, a nurturing environment where she could be herself, surrounded by her family’s love. She gained attention with a viral video of her rendition of Jenni Rivera’s “Que Me Vas a Dar.” Palafox delivers each note with profound emotion and precision, leaving even the accompanying mariachi violinist in awe. . .”
[Click here to read more]
—
(6). Echoes of the Latent Present: Listening to Lags, Delays, and Other Temporal Disjunctions
—by Matthew Tomkinson

“Sometime last year, during a recent deep clean of the apartment, I pulled out a wooden chest that my father built for me when I was ten, a pine-scented time capsule of that period of my life, full of assorted construction-paper projects and faded movie tickets. Buried underneath all this loose paper, set apart by a shiny laminated cover, is the first “novel” I ever wrote, our final project in fourth grade, which was really just a few typed pages folded and stapled together, held between a cardstock cover. In this book, I write about a mall janitor with magic powers, who uses his mop handle to transform villains into piles of fabric, and who time travels throughout history by way of a magic corvette (clearly, I had just seen a certain Robert Zemeckis film).
Having rediscovered this story, I am struck by the realization that my writerly voice has hardly changed. I am still drawn to the same hokey surrealism, the same comic book sensibilities, the same spirit of hand-stapled publishing projects. This is to say: I could not help but to identify in this proto-novel traces of my work to come, early impulses that echo throughout my present practice. As Lisa Robertson puts it in an interview: “Defunct forms resurface after years of latency. New work speaks with old work, as well as with the future.”.”
[Click here to read more]
—
by Emily Collins

“When the COVID-19 global pandemic began, news reports and studies throughout the world began citing a lot of sound-based statistics: drastic reductions in noise pollution in urban centres, AI recordings of cellphone coughs, shifting soundscapes at home with new routines and work settings, and sonic sensitivities cultivated in quarantine and isolation. At the same time, in conjunction with these new research studies and areas of interest, there was an outpouring of calls for sound recordings and contributions to digital archival sound projects, such as Sounds of Pandemia, the Pandemic Diaries project, Sound of the Earth: The Pandemic Chapter, Sounds like a Pandemic? (SLAP?), and Stories from a Pandemic, just to name a few. A perceptive post by Sarah Mayberry Scott (2021)outlines the stakes for these types of initiatives grounded in a particular yet ever-changing historical moment, and the stakes of listening (in its attentiveness) and sound (in its persuasive power) more broadly, though undoubtably mediated and defined by power relations in their various social and the cultural contexts. . .”
[Click here to read more]
—
—(4). Wingsong: Restricting Sound Access to Spotted Owl Recordings
by Julianne Graper

“I am not a board games person, yet I always seem to find myself surrounded by them. Such was the case one August evening in 2023, during a round of the bird-watching-inspired game, Wingspan. Released in 2019 by Stonemaier Games, designer Elizabeth Hargrave’s creation is credited with a dramatic shift in the board game industry. The game received an unparalleled number of awards, including the prestigious 2019 Kennerspiel des Jahres (Connoisseur Game of the Year), and an unheard of seven categories of the Golden Geek Awards, including Best Board Game of the Year and Best Family Board Game of the Year. In addition to causing shifts in typical board game topic, artistry, and demographic, Wingspan has led many board game fans to engage with the natural world in new ways, even inspiring many to become avid birders.
Following the game’s rise to popularity, developer Marcus Nerger released an app, Wingsong which allows players to scan each of the beautifully illustrated cards and play a recording of the associated bird’s song. On the evening in question, the unexpected occurred when I scanned the Spotted Owl (Strix occidentalis) card and received a message that read:
Playback of this birds[sic] song is restricted. . .”
[Click here to read more]
—
—(3). Rhetoric After Sound: Stories of Encountering “The Hum” Phenomenon
by Trent Wintermeier

“‘So I have heard The Hum… The rest of what I’m about to tell you is beyond reasoning, and understanding.” Here, in a Reddit post, Michael A. Sweeney prefaces their story of their first encounter with “the hum,” an unexplained phenomenon heard by only a small percentage of listeners around the world. The hum is an ominous sonic event that impacts communities from Australia to India, Scotland to the United States. And as Geoff Leventhall writes in “Low Frequency Noise: What We Know, What We Do Not Know, and What We Would Like to Know,” the hum causes “considerable problems” for people across the globe—such as nausea, headaches, fatigue, and muscle pain—as it continues to be an unsolved “acoustic mystery” (94). . .”
[Click here to read more]
—
(2). Listening to MAGA Politics within US/Mexico’s Lucha Libre
by Esther Díaz Martín and Rebeca Rivas

“The announcer’s piercing “lucharaaaaaán” cries from the middle of the ring proclaims the constitutional two-out-of-three-falls rule of lucha libre. But before the famous cry rings out to set the stage for the spectacularized acrobatic combat between costumed warriors, their theatrical entrances set the all-important emotional stakes of the battle. The entrances are loud, campy, interactive exchanges between luchadores and spectators. An entrance song itself cues the luchador’s persona: a cumbia could signal a técnico (a good guy); a heavy metal song more than likely indicates a rudo (a bad guy) typically donning black, death-themed getups. Luchadores saunter into the arena, stopping to pose, high five their fans, and verbally heckle their opponents. The storylines of good versus evil, betrayal and revenge, or humility versus arrogance are some of the more standard plots that motivate spectators to adamantly cheer for the favorite and jeer for the foe.
The sonic exchanges between luchadores’ and spectators before, during, and after the fight positions lucha libre as much more than a sport. And while the term spectators, suggests the privileged act of watching or viewing; here, we expand spectators within lucha libre arena to mean “a call to witness” (á la Chela Sandoval). Put simply, lucha libre is a cultural phenomenon where contemporary cultural, social, and political anxieties are often tapped as fodder for theatrical plots. In the U.S./Mexico’s sister cities of El Paso, Texas and Ciudad Juarez, Chihuahua, the political realities of border enforcement, immigration politics, and racial tensions are loudly heard and placed on display. . .”
[Click here to read more]
—
(1). to follow an invisible creek: in search of a decolonial soundwalk praxis
by ameia camielle smith

“in the context of the rapid rise of big tech in san francisco, california, the perspective of land as perpetually exploitable is ever-present. tech-sponsored development projects are always framed by the city as being motivated by care and consideration for residents, and sometimes as being motivated by environmentalism. in reality, the displacement and destruction that results from projects like these falls primarily on poor people of color, and their homes, gardens, businesses, community spaces, and schools. similarly, large-scale development projects more often than not have devastating impacts on the land – whether it’s the land that’s being built over or the sacrifice zone elsewhere. perhaps the electric cars of san francisco are thought to represent clean energy and a healthy modern city, but the manufacturing of these cars is predicated upon extensive mining and exploitative and extractive labor outside far outside the city’s borders. and these cars drive over flattened creeks and sand dunes turned to asphalt—through gentrified neighborhoods on stolen land of the Ramaytush Ohlone, people who are still alive and fighting for sovereignty on their traditional territory, and who remain stewards of the land.
these disparities are present in the sounds of the bay area. sound, quite literally, does not exist in a vacuum. the presence of sound thus implies the presence of something outside of that sound; in every sound we hear, there is also information about the context that surrounds it. and the sounds that we do hear say something about the value of the sounds that we don’t. however, i want to argue for a soundwalking praxis that does not settle for the sounds that most easily reach the ear, as in the freeway noise or the planes passing above or the white people on the street, but that reaches beyond to listen for the negative sonic space that is always present and creating itself in the spaces between what we perceive as audible. in my understanding, this is a practice of giving life to that which capitalism/white supremacy/colonialism renders dead, a practice of centering the life that is otherwise stepped on, forgotten, discarded, silenced. listening for the ecologies of the dispossessed. for proof of life, insisting. this is a decolonial soundwalk praxis. . .”
[Click here to read more]
—
Featured Image “underwater scream” by Flickr User Smellslikeupdog CC BY-ND 2.0
—

REWIND! . . .If you liked this post, you may also dig:
The Top Ten Sounding Out! Posts of 2023!
The Top Ten Sounding Out! Posts of 2020-2022!
The Top Ten Sounding Out! Posts of 2019!
The Top Ten Sounding Out! Posts of 2018!
The Top Ten Sounding Out! Posts of 2017!






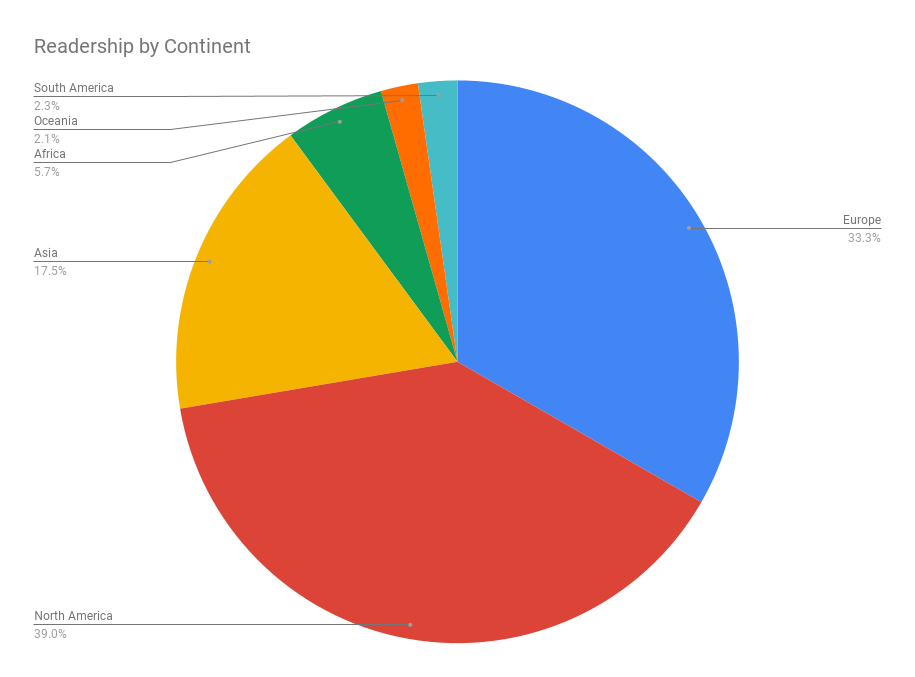
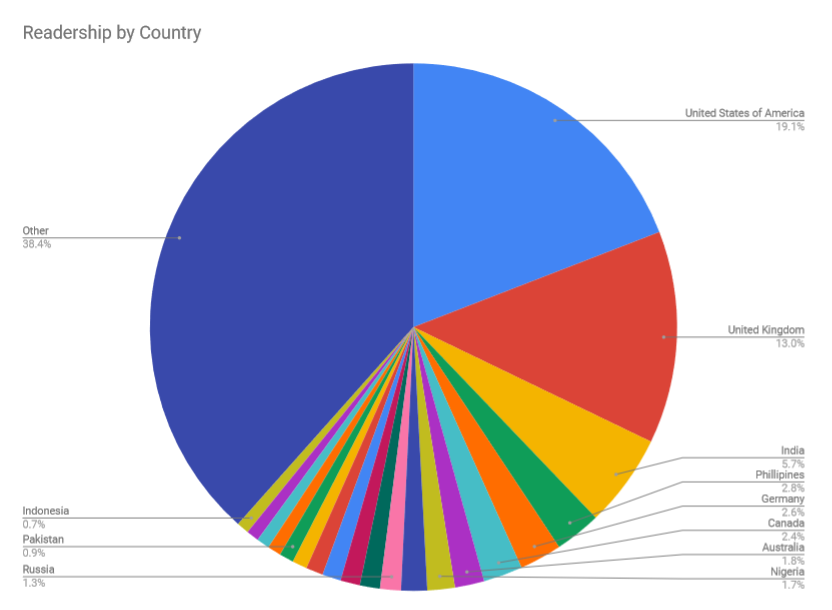
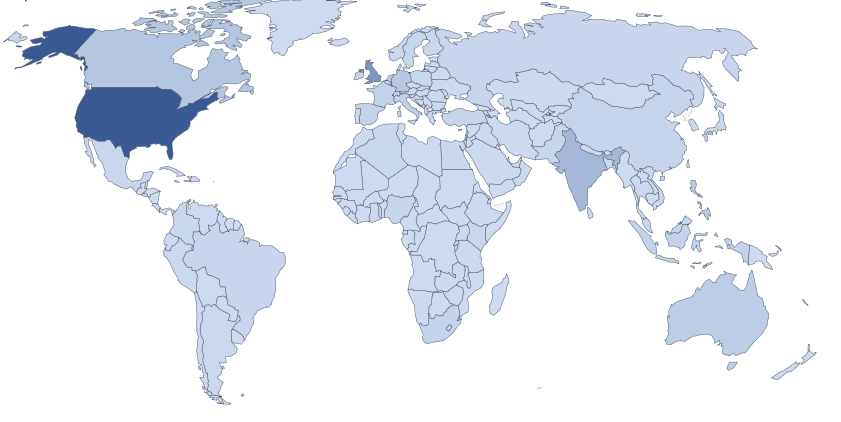
































 Credit: Matteo Principi
Credit: Matteo Principi The 60th Anniversary of Praxis. CC 4.0 by ISSA School / BONK productions
The 60th Anniversary of Praxis. CC 4.0 by ISSA School / BONK productions CC 4.0 by ISSA School / BONK productions
CC 4.0 by ISSA School / BONK productions For a Global Mutiny Against an Empire of Negligence. CC 4.0 by ISSA School / BONK productions
For a Global Mutiny Against an Empire of Negligence. CC 4.0 by ISSA School / BONK productions Credit: Matteo Principi
Credit: Matteo Principi Links to the pdf, epub and the Lulu page to order a paper copy can be found
Links to the pdf, epub and the Lulu page to order a paper copy can be found 