Have you ever wondered why conversations go wrong? Why your attempt at communication missed its intended target? Is it even possible to measure and calculate the success rate of a conversation? Economists like Georg Weizsacker believe that this is very possible. As a behavioural economist, his research interests include game theory, decision theory and applied microeconomics, which in turn has led to him using game theory to explore why people misunderstand each other. Georg explores this concept in his upcoming title Misunderstandings: False Beliefs in Communication; published and made accessible to scholars everywhere by Open Book Publishers.
What is Game Theory?
Both decision theory and game theory concern the reasoning process underlying people’s choices, that is, how their desires, beliefs, and other attitudes combine in a way that make people choose one option over another. (Stockholm University, 2023). Game theory focuses on the interactions between different decision makers as they try to make the best decision based on their beliefs about what others will choose (Stockholm University, 2023). You could apply this theory when having a conversation with someone. According to Georg Weizsacker, during a conversation, you will consider three things about the speaker as they talk: their actions, their type and their understanding of the state of the world. These three things will also influence how you respond to their statement, and, if both speaker and listener are considered to be rational decision makers in line with game theory, you will both consider how your respective understanding of the other person’s type and knowledge of the state of the world, impacts your chosen actions. Actions include spoken statements and any action that may occur after the conversation has taken place. A person’s type refers to their personality, their disposition at the time of conversation and their personal preferences. It is also likely that each person knows different things about the state of the world and through this conversation they may exchange information with each other, that contributes to or alters each person’s respective perceptions on the state of the world.
Are our beliefs distorted?
Georg Weizsacker would like to encourage further research into false beliefs within communication and how they lead to misunderstandings between people. He offers the reader 18 questions to consider when measuring and predicting the success rate of a single-step conversation between two people. It is important to note that it is difficult to predict the outcome of a conversation using mathematical models when the conversation is complex, involving multiple people and steps. Therefore, to keep things clear and scientific, Georg has allowed for some variables to remain constant. For example, only single-step conversations are studied, the book assumes that each person knows their own type and the uncertainty about other people’s types is assumed to be statistically independent of the uncertainty about the state of the world (Georg Weizsacker).
The book aims to answer this research question: “What are the beliefs that would justify leading the conversation in the way that people lead it?” Georg Weizsacker measures whether or not these beliefs are true or false and encourages the reader to think about how their false beliefs concerning another person’s actions, type or state of the world can lead to misunderstandings in conversation with them. Essentially, the 18 questions posed within the main body of the text, explore whether our beliefs about these uncertain aspects (action, type or state of the world) are distorted (Georg Weizsacker). If they are distorted, then our communication attempt may fail or not reach its intended target.
Do we need target practice?
Georg presents his readers with three colour-coded case studies that represent three single-step conversations between two individuals, or interlocutors, as he calls them. In each conversation, the speaker wants the listener to do something but the listener rejects it because there are misunderstandings made on the part of the speaker towards the listener. Georg describes a misunderstanding as ‘a belief that misses its target’. (Georg Weizsacker).
Each case study explores a misunderstanding in detail, with reference to the extant literature on game theory and how it can be used to understand decision making. First, we have Rachel (a senior researcher) who asks her boss to fund a new research centre but is turned down by him. Second, Dimitri (an office worker) who doesn’t realise that his colleague Agniezka is considering switching teams because their product design proposal has been rejected, despite high hopes and invested effort on her part. Finally, we have Steve (a young child) who asks Ralph (the school bully) to play with him and gets pushed instead because Ralph is a troubled boy who struggles to process and regulate his emotions in a healthy way.
Should I read this book?
If you would like to learn more about misunderstandings and how we can better communicate with each other, then this book is for you. You do not need a strong background in Microeconomics to appreciate this book; however, this knowledge will be helpful when considering the mathematical models used by Georg Weizsacker for conversation pattern identification and prediction. Otherwise, if you are a keen economist and enjoy game theory and discussions surrounding decision making practices and how they can contribute to effective human interaction, this book will be a great read or asset to use when designing a seminar for university students or as a source to cite within your own academic research, if applicable. I, for one, did enjoy the theoretical discussion and the applied case studies. It is an interesting idea to ponder over and apply within the context of my own conversations with people, particularly if I want something from them! I don’t want to miss my target if I can help it, but this book definitely offers valuable insight into how communication issues can be solved going forward.
Sources
Stockholm University - Decision Theory and Game Theory
In this edition, we've got a treasure trove of updates, insights, and exciting plans to share with you. Get ready to dive into the world of knowledge, innovation, and our upcoming releases. Here's a sneak peek of what's inside:
Announcements
Our Prize-winning title
Celebrating 15 Years of Knowledge, Innovation, and Open Access!
Open Access Books Network
Call for Proposals: Experimental Book Pilot Projects
Open Access Week 2023: Embracing 'Community over Commercialization'
Books, Resources and Reviews
Featured Book
New Open Access Publications
Forthcoming Open Access Publications
New Blogs and Resources
Call for Proposals
Latest Reviews
Winner of Best History in the category Best Historical Research in Classical Music in the 2023 Association for Recorded Sound Collections Awards for Excellence
Initiated in 1991, the ARSC Awards for Excellence acknowledge authors of books, articles, or recording liner notes that showcase the finest contemporary achievements in recorded sound research. Through these awards, ARSC acknowledges the significant contributions of these individuals, seeks to inspire others to uphold similar high standards, and endeavors to boost the readership of their exceptional work.
Celebrating 15 Years of Knowledge, Innovation, and Open Access!
Fifteen years ago, our journey began with a vision for knowledge, innovation, and the fundamental belief in the power of open access. Today, we celebrate this remarkable milestone and express our heartfelt gratitude to each one of you who has been a part of this incredible journey.
Thank you for your unwavering support, enthusiasm, and commitment to advancing scholarship. It's your passion for open access that has driven us to make knowledge more accessible and fostered innovation in ways we couldn't have imagined.
As we commemorate this significant anniversary, we're excited to share a special blog post marking this momentous occasion. 15 Years of Open Book Publishers: An Interview with Alessandra Tosi and Rupert Gatti is now live on our website. Dive into this exclusive interview, exploring the journey, challenges, and aspirations of our founders as they reflect on the past 15 years and the future of open access.
Join us in celebrating this milestone by reading the insightful interview that encapsulates the essence of our journey.
Here's to the next chapter, where our collective efforts will forge a path toward a more knowledgeable and inclusive world.
Open Access Books Network: What they learned from their survey and how they're planning to respond!
Over the summer, the OABN initiated its (not a) survey to gain deeper insights into the OABN community.
The survey was launched because, during the three years of running the OABN, the community has expanded, prompting them to understand: Who are the current members, what their expectations are from the network, and how they could contribute to it. Through the two blog posts below they explore:
CALL FOR PROPOSALS: EXPERIMENTAL BOOK PILOT PROJECTS
Copim is delighted to announce support and funding for three experimental book publishing pilots. These book pilot projects will be developed with Open Book Future’s Experimental Publishing Group, supported by Coventry University, and will be overseen by the Open Book Collective. They are inviting individuals and project teams to submit proposals for experimental, long-form scholarly book projects.
Open Access Week 2023: Embracing 'Community over Commercialization'
Reflecting on the recently concluded Open Access Week, we celebrated the theme "Community over Commercialization." This pivotal focus prompted insightful discussions about approaches to open scholarship that prioritize the best interests of the public and the academic community.
Throughout the week, engaging conversations revolved around the consequences of prioritizing commercial interests over those of the research community. Participants explored thought-provoking questions, considering the impact of profit-centric models on knowledge production and the balance between personal data use and academic freedom. The discussions also contemplated whether commercialization could truly serve the public interest and sought alternative, community-driven infrastructure such as preprint servers, repositories, and open publishing platforms to better serve the research community and the public. As a contributor to this year's Open Access Week, Open Book Publishers released a series of blog posts and author interviews that delved into the theme of 'Community over Commercialization'. These discussions underlined our commitment to representing this theme and advancing the cause of open access in scholarly publishing. See below:
Though Open Access Week has concluded, the conversations and initiatives surrounding 'Community over Commercialization' continue to be relevant and essential throughout the year.
For a deeper understanding of the International Open Access Week, you can explore past events and discussions at openaccessweek.org. To revisit the shared insights and conversations, check out the official hashtag #OAWeek on Twitter.
Shépa: ‘explanation’ or ‘elucidation’ in Tibetan. A form of oral poetry sung antiphonally in a question-and-answer style.
This book contains a unique collection of Tibetan oral narrations and songs known as Shépa, as these have been performed, recorded and shared between generations of Choné Tibetans from Amdo living in the eastern Tibetan Plateau. Presented in trilingual format — in Tibetan, Chinese and English — the book reflects a sustained collaboration with and between members of the local community, including narrators, monks, and scholars, calling attention to the diversity inherent in all oral traditions, and the mutability of Shépa in particular.
From creation myths to Bon and Buddhist cosmologies and even wedding songs, Shépa engages with and draws on elements of religious traditions, historical legacies and deep-seated cultural memories within Choné and Tibet, revealing the multi-layered conceptualization of the Tibetan physical world and the resilience of Tibetan communities within it. This vital and unique collection, part of the World Oral Literature Series, situates Shépa in its ethnographic context, offering insights into the preservation and revitalization of intangible cultural heritage in the context of cultural Tibet, Indigenous studies and beyond.
Scholars and students in the fields of anthropology, linguistics, ethnic and minority relations, critical Indigenous studies, Tibetan studies, Himalayan studies, Asian studies and the broader study of China will find much to reward them in this book, as will all readers interested in the documentation and preservation of endangered oral traditions, intangible cultural heritage, performance and textuality, and Tibetan literature and religions.
Endorsements
This trilingual publication is a remarkable accomplishment and a landmark publication in Tibetan studies, making research findings accessible to the community for whom Shepa is a living practice. This is a welcome first publication on the tradition of Shepa as it exists in Chone, in the Amdo region of Eastern Tibet. The collaborative team have contextualized Shepa oration as part of Tibet's rich tradition of oral narratives, and have meticulously transcribed the oral narrations that existed in the memories of the older generation. They provide readers with faithful translations, and preserve the joyous mode of storytelling that fills the grassland.
Tsering Shakya Associate Professor and Canada Research Chair in Religion and Contemporary Society in Asia at the Institute for Asian Research, School of Public Policy and Global Affairs, University of British Columbia.
This book is a massive achievement, and the product of a considerable amount of painstaking work. The trilingual edition of Shépa provides a unique insight into an important regional tradition, and the first opportunity for Anglophone audiences to approach this tradition. Rich introductory material also helps to set these materials in the complex cultural tapestry of the eastern Tibetan Plateau through describing how their present form is influenced by local religious and cultural history, Tibetan language verbal art, and with the People’s Republic of China’s heritage regime. More broadly, the study of Tibetan oral traditions and vernacular cultures (and of Choné) are woefully underrepresented in English-language Tibetological research, and this makes a unique contribution to the broader field. It is a valuable and original contribution that only this research team could produce.
Timothy Thurston Associate Professor in the Study of Contemporary China, University of Leeds
Shépa: The Tibetan Oral Tradition in Choné is a remarkable achievement on many fronts. The book contributes a landmark study of Shépa as embodying a wide-ranging set of discursive forms [and] likewise presents a nuanced reflection on the relationships between poetry, narrative, and performativity, as well as the oral and literary practices of knowledge production more broadly. The book stands as one of the most detailed records to date of a singular expression of Tibetan oral performance that thrives as a contemporary practice even as it is rooted in a religious and cultural history extending back to the earliest periods of Tibetan civilization. Finally, this work serves as a model of collaborative and interdisciplinary scholarship [and] will make an impactful and lasting contribution to our understanding of Shépa and to Tibetan oral traditions more broadly.
Andrew Quintman Associate Professor, Department of Religion and the College of East Asian Studies, Wesleyan University
These past months we have released 12 new Open Access titles:
The Linguistic Classification of the Reading Traditions of Biblical Hebrew: A Phyla-and-Waves Modelby Benjamin Paul Kantor In recent decades, the field of Biblical Hebrew philology and linguistics has been witness to a growing interest in the diverse traditions of Biblical Hebrew. Indeed, while there is a tendency for many students and scholars to conceive of Biblical Hebrew as equivalent with the Tiberian pointing of the Leningrad Codex as it appears in Biblia Hebraica Stuttgartensia (BHS), there are many other important reading traditions attested throughout history.
William Moorcroft (1872-1945) was one of the most celebrated potters of the early twentieth century. His career extended from the Arts and Crafts movement of the late Victorian age to the Austerity aesthetics of the Second World War. Rejecting mass production and patronised by Royalty, Moorcroft’s work was a synthesis of studio and factory, art and industry. He considered it his vocation to create an everyday art, both functional and decorative, affordable by more than a privileged few: ‘If only the people in the world would concentrate upon making all things beautiful, and if all people concentrated on developing the arts of Peace, what a world it might be,’ he wrote in a letter to his daughter in 1930.
This deeply researched collection offers a comprehensive introduction to the eighteenth-century trade in street literature – ballads, chapbooks, and popular prints – in England and Scotland. Offering detailed studies of a selection of the printers, types of publication, and places of publication that constituted the cheap and popular print trade during the period, these essays delve into ballads, slip songs, story books, pictures, and more to push back against neat divisions between low and high culture, or popular and high literature.
Technologies shape who we are, how we organize our societies and how we relate to nature. For example, social media challenges democracy; artificial intelligence raises the question of what is unique to humans; and the possibility to create artificial wombs may affect notions of motherhood and birth. Some have suggested that we address global warming by engineering the climate, but how does this impact our responsibility to future generations and our relation to nature? This book shows how technologies can be socially and conceptually disruptive and investigates how to come to terms with this disruptive potential.
In dit rigoureuze en noodzakelijke boek brengt Kristien Hens bio-ethiek en filosofie van de biologie bij elkaar, met het argument dat het ethisch noodzakelijk is om in het wetenschappelijk onderzoek een plaatsje vrij te houden voor de filosofen. Hun rol is behalve ethisch ook conceptueel: zij kunnen de kwaliteit en de coherentie van het wetenschappelijk onderzoek verbeteren door erop toe te zien dat specifieke concepten op een consistente en doordachte manier worden gebruik binnen interdisciplinaire projecten. Hens argumenteert dat toeval en onzekerheid een centrale rol spelen in de bio-ethiek, maar dat die in een spanningsrelatie kunnen raken met de pogingen om bepaalde theorieën ingang te doen vinden als wetenschappelijke kennis: bij het beschrijven van organismen en praktijken creëren we op een bepaalde manier de wereld. Hens stelt dat dit noodzakelijk een ethische activiteit betreft.
This volume is the result of the 2021 session of the Linguistics and the Biblical Text research group of the Institute for Biblical Research, which addresses the history, relevance, and prospects of broad theoretical linguistic frameworks in the field of biblical studies. Cognitive Linguistics, Functional Grammar, generative linguistics, historical linguistics, complexity theory, and computational analysis are each allotted a chapter, outlining the key theoretical commitments of each approach, their major concepts and/or methods, and their important contributions to contemporary study of the biblical text.
In this rich memoir, the first of two volumes, Paul Farmer traces the story of A39, the Cornish political theatre group he co-founded and ran from the mid-1980s to the early 1990s. Farmer offers a unique insight into A39’s creation, operation, and artistic practice during a period of convulsive political and social change.
Transparent Minds explores the intersection between neuroscience and science fiction stories. Paul Matthews expertly analyses the narratives of humans and nonhumans from Mary Shelley to Kazuo Ishiguro across 200 years of the genre. In doing so he gives lucid insight into the meaning of existence and self-awareness. Rigorously researched and highly accessible, Matthews argues that psycho-emotional science fiction writers both imitate and inform alien and post-human consciousnesses through exploratory narratives and metaphor.
In today’s ‘publish or perish’ academic setting, the institutional prizing of quantity over quality has given rise to and perpetuated the dilemma of predatory publishing. Upon a close examination, however, the definition of ‘predatory’ itself becomes slippery, evading neat boxes or lists which might seek to easily define and guard against it. This volume serves to foreground a nuanced representation of this multifaceted issue. In such a rapidly evolving landscape, this book becomes a field guide to its historical, political, and economic aspects, presenting thoughtful interviews, legal analysis and original research. Case studies from both European-American and non-European-American stakeholders emphasize the worldwide nature of the challenge faced by researchers of all levels.
After decades of turbulence and acute crises in recent years, how can we build a better future for Higher Education? Thoughtfully edited by Laura Czerniewicz and Catherine Cronin, this rich and diverse collection by academics and professionals from across 17 countries and many disciplines offers a variety of answers to this question. It addresses the need to set new values for universities, trapped today in narratives dominated by financial incentives and performance indicators, and examines those “wicked” problems which need multiple solutions, resolutions, experiments, and imaginaries.
What do we expect when we say something to someone, and what do they expect when they hear it? When is a conversation successful? The book considers a wide set of two-person conversations, and a bit of game theory, to show how conversational statements and their interpretations are governed by beliefs. Thinking about beliefs is suitable for communication analysis because beliefs are well-defined and measurable, allowing to differentiate between successful understandings and their less successful counterparts: misunderstandings.
In this fascinating book David Ingram traces the history of information technology and health informatics from its pioneers in the middle of the twentieth century to its latest developments.
Genetic Inroads into the Art of James Joyce by Hans Walter Gabler This book is a treasure trove comprising core writings from Hans Walter Gabler‘s seminal work on James Joyce, spanning fifty years from the analysis of composition he undertook towards a critical text of A Portrait of the Artist as a Young Man, through the Critical and Synoptic Edition of Ulysses, to Gabler‘s latest essays on (appropriately enough) Joyce’s sustained artistic innovation.
This volume presents an exploration of Digital Humanities (DH), a field focused on the reciprocal transformation of digital technologies and humanities scholarship. Central to DH research is the practice of modelling, which involves translating intricate knowledge systems into computational models. This book addresses a fundamental query: How can an effective language be developed to conceptualize and guide modelling in DH?
Jane Eyre, written by Charlotte Brontë and first published in 1847, has been translated more than five hundred times into over sixty languages. Prismatic Jane Eyre argues that we should see these many re-writings, not as simple replications of the novel, but as a release of its multiple interpretative possibilities: in other words, as a prism.
We have various Open Access series all of which are open for proposals, so feel free to get in touch if you or someone you know is interested in submitting a proposal!
Global Communications
Global Communications is a book series that looks beyond national borders to examine current transformations in public communication, journalism and media. Special focus is given on regions other than Western Europe and North America, which have received the bulk of scholarly attention until now.
St Andrews Studies in French History and Culture
St Andrews Studies in French History and Culture, a successful series published by the Centre for French History and Culture at the University of St Andrews since 2010 and now in collaboration with Open Book Publishers, aims to enhance scholarly understanding of the historical culture of the French-speaking world. This series covers the full span of historical themes relating to France: from political history, through military/naval, diplomatic, religious, social, financial, cultural and intellectual history, art and architectural history, to literary culture.
Studies on Mathematics Education and Society
This book series publishes high-quality monographs, edited volumes, handbooks and formally innovative books which explore the relationships between mathematics education and society. The series advances scholarship in mathematics education by bringing multiple disciplinary perspectives to the study of contemporary predicaments of the cultural, social, political, economic and ethical contexts of mathematics education in a range of different contexts around the globe.
The Global Qur'an
The Global Qur’an is a new book series that looks at Muslim engagement with the Qur’an in a global perspective. Scholars interested in publishing work in this series and submitting their monographs and/or edited collections should contact the General Editor, Johanna Pink. If you wish to submit a contribution, please read and download the submission guidelines here.
The Medieval Text Consortium Series
The Series is created by an association of leading scholars aimed at making works of medieval philosophy available to a wider audience. The Series' goal is to publish peer-reviewed texts across all of Western thought between antiquity and modernity, both in their original languages and in English translation. Find out more here.
Applied Theatre Praxis
This series publishes works of practitioner-researchers who use their rehearsal rooms as "labs”; spaces in which theories are generated and experimented with before being implemented in vulnerable contexts. Find out more here.
Digital Humanities
Overseen by an international board of experts, our Digital Humanities Series: Knowledge, Thought and Practice is dedicated to the exploration of these changes by scholars across disciplines. Books in this Series present cutting-edge research that investigate the links between the digital and other disciplines paving the ways for further investigations and applications that take advantage of new digital media to present knowledge in new ways. Proposals in any area of the Digital Humanities are invited. We welcome proposals for new books in this series. Please do not hesitate to contact us (a.tosi@openbookpublishers.com) if you would like to discuss a publishing proposal and ways we might work together to best realise it.
From my own experience as an educational scholar in Malaysia, I suspect that many of the book’s insights will resonate with, as well as challenge and surprise interested readers. The book is an engaging read, achieving that oft-elusive balance between (academic) rigour and accessibility. [...] I felt that I benefited most from Chapter 3, on the governance of education systems, where the authors’ close analysis of governance arrangements—the distribution of power and responsibilities between levels of government, financial incentives, etc.—was eye-opening and incisive. In particular, I appreciated the authors’ nuanced intervention in the centralising vs. decentralising education debate, which will no doubt be of interest to many. [...] Chapter 6 then allows the reader to view the task of reform through the prism of front-line policymaking. While framed as the authors’ personal anecdote, this chapter nonetheless vividly illustrates the complex interplay between politics and policy, including the roles of political parties, the media and PISA. It is a sobering account of the political realities of education reform, conflicts of (vested) interests, and the questionable role of non-state actors like PISA.[...] Dire Straits deserves a wide readership, particularly with educationists outside academia, and is essential reading for university courses in comparative education and education policy.
It seeks to offer the means to overcome the ideological schism and escape the trap which education systems seem to fall into. The authors strongly advocate for sparing educational policies the ideological disputes, eliminating obstacles on the way to evidence-based education reforms. More importantly, they strive to assess how robust policy recommendations are, so they can be used as evidence-based references for any reforms. The strength of their discourse lies in the extensive descriptions and explanations of what, how, and why educational policies and reforms succeed or fail. The comparative examination of specific cases of countries to illustrate dire-straits education reforms and how international surveys are used to direct these reforms is based on a detailed approach, supported by rich and interesting arguments, with clear and straightforward viewpoints and stances. As suggested by the meaningfully loaded title, the discussion and analysis untangle the complex relationships between numerous influential factors which significantly impact education. Diana Aboulebde Educational Research and Evaluation: An International Journal on Theory and Practice, 2023. doi:10.1080/13803611.2023.2261907
Personal diaries can provide valuable insights into many topics of interest to urban historians, and the diaries transcribed in this volume are no exception […] Hobbs has written a useful introduction to the life and work of Hewitson and the team have also assembled a full bibliography of his work, a family tree, a list of the books read by Hewitson, a glossary of technical and dialect terms and an explanatory list of all the people mentioned in the diary. The volume is very carefully referenced and provides a scholarly introduction to the writings of Hewitson […] Hobbs argues persuasively that what is distinctive and important about these diaries is that they provide a detailed picture of the work of a prolific journalist working in a Lancashire town in the second half of the nineteenth century, where he saw and reported on numerous aspects of urban politics, religion and everyday life […] the transcription and publication of these diaries is a valuable contribution to the history of journalism, and provides useful commentary on some of the urban areas of north-west England in the second half of the nineteenth century. Colin PooleyUrban History, vol. 50, no. 3, 2023. doi:10.1017/S0963926823000226
In today’s media climate of fake news and clickbait, we are all well aware of the dangers of false information. This begs the question—why? Why do people publish information they don’t know is accurate? This problem besets academic publishing too. A collaboration between five writers, Amy Koerber, Jesse C. Starkey, Karin Ardon-Dryer, Lyombe Eko, and Kerk F. Kee, this book works to establish the motives behind predatory publishing—in which academic research is published without having been satisfactorily peer-reviewed, often in return for a fee—and explores the resultant implications of the practice. In academic life, one of the many challenges that may face scholars is how they get their work published. The Predatory Paradox: Ethics, Politics, and Practices in Contemporary Scholarly Publishing is designed as an advisory guide for ‘researchers, academic administrators, publishing professionals and other stakeholders’ to equip readers with the knowledge and ideas necessary to be both ethical and successful in the world of scholarly communication.
One of the foundational points of the book is the term ‘predatory publishing’. The exact meaning of this term has been debated since its conception, however in 2019, a Nature paper reported that after a dedicated discussion between leading scholars and publishers from ten countries, a definition was finally determined. It states that:
Predatory journals and publishers are entities that prioritize self-interest at the expense of scholarship and are characterized by false or misleading information, deviation from best editorial and publication practices, a lack of transparency, and/or the use of aggressive and indiscriminate solicitation practices. (Grudniewicz et al, 2019)
The book considers not only how predatory publishing may occur, but the long-term repercussions of the practice. For example, it delves into the longevity of hoax articles, in that they can be presented as true by a predatory publisher and can enter the research ecosystem, being cited long after the hoax has been uncovered. In turn, this exemplifies how such articles can reveal weaknesses in the system of scholarly publishing itself.
From these dilemmas, academics have created new ways to prove the legitimacy of their work, in the hope that readers will be able to use such tools to ensure that these articles can be trusted. One way in which these systems could be improved—as suggested by the book—is by increasing the transparency of such procedures. The idea here is that with greater ‘openness’ there will be fewer chances for predatory publishing to take advantage of a lack of information, such as hidden datasets or reviewer reports, to peddle their misinformation. With greater transparency, readers can check supposed ‘facts’ for themselves, confirming the conclusions presented in a text.
The authors also consider how scholars can take certain matters into their own hands—by teaching the dangers and hallmarks of predatory publishing, and therefore raising awareness, we can prepare people to avoid misinformation and inaccuracy in their research. There are limitations to this approach, however, due to the pace of change in academic publishing. While experienced scholars have always taught the next generation, these new challenges are some that senior academics have often not faced before. The scholars of today, young and old, must recognise that the environment of scholarly research is fluid and ever-changing if they hope to traverse it with any chance of success.
In addition, we must consider how universities are responding to this threat. Without a doubt, universities have recognised concerns around this subject, yet evaluation of the training provided to respond raises the question of whether this is enough. To identify gaps in teaching, this book argues that we must consider resources that are available to researchers and appraise whether these resources are sufficient to support scholars in their pursuit of knowledge.
The authors of this book have stated their aims for the publication:
we hope to leave readers with a set of tools and knowledge that makes them prepared to succeed in the game of scholarly publishing and to mentor those who come after them to be similarly prepared and equipped. (Grudniewicz, 2023)
Overall, as the book argues, the fact is that predatory publishing is made up of numerous grey areas and individuals have to be responsible when navigating these; it cannot be defined with stark lines drawn between texts and their commissioners to identify those who are indeed predatory and those who, most certainly, are not. There are numerous challenges surrounding the confirmation of quality in scholarly publishing, but perhaps the only true way to determine whether a publisher or article can be considered predatory is to assess numerous aspects of the research, not just how texts are written. Not only that, but we must consider that the incentives driving research assessment are also those that drive the demand for predatory publishing.
A doctor of medicine and a scholar of literature must both be held to the same standard in any publication–their ideas must be well-defined, their methods clearly documented, and their research conducted fairly. This book is informative and instructive in many ways, reinforcing the foundations of good research and building on their appearance in contemporary scholarly publishing. Anyone in academia would find this text a valuable resource for their own research and exploration of the world of scholarly publishing.
This is an Open Access title available to read and download for free or to purchase in all available print and ebook formats below.
Grudniewicz, A., Moher, D., Cobey, K.D., Bryson, G.L., Cukier, S., Allen, K., Ardern, C., Balcom, L., Barros, T., Berger, M., Ciro, J.B., Cugusi, L., Donaldson, M.R., Egger, M., Graham, I.D., Hodgkinson, M., Khan, K.M., Mabizela, M., Manca, A. and Milzow, K. (2019). ‘Predatory journals: no definition, no defence’, Nature, 576.7786: pp.210–212. Available at: https://doi.org/10.1038/d41586-019-03759-y
Koerber, A., Starkey, J.-C., Ardon-Dryer, K., Eko, L. and Kee, F.-K. (2023) The Predatory Paradox: Ethics, Politics, and Practices in Contemporary Scholarly Publishing. Cambridge, UK: Open Book Publishers.
In an era where the democratization of knowledge is more crucial (and accessible) than ever, the paradigm of Open Access publishing emerges as a cornerstone. At its core, Open Access is about dismantling barriers—be they financial, geographic, or institutional—that hinder the free exchange of scholarly insights. Open Book Publishers, being at the vanguard of this movement, champions a model where collaboration and community involvement aren't mere byproducts, but are fundamental ethos. This International Open Access Week, we delve into the collaborative nature of open access publishing, underscoring how community engagement and knowledge sharing are instrumental in advancing research.
The scholarly landscape has long been shackled by traditional hierarchical structures which, while fostering a culture of exclusivity, have often stifled the free flow of ideas. The emblematic case of teaching versus research institutions delineates this dichotomy. One of my recent articles highlights this need and presents a model to address the bulwark of traditional academic research and publishing. The Role of Collaborative Authorship in Decentered Research Innovation illuminates the prevalent structures within these institutions either promote a culture of teaching and learning with a focus on student engagement, or a culture of scholarship with faculty members delving into research while graduate students shoulder the teaching responsibilities. However, this bifurcation inadvertently erects barriers to holistic academic evolution.
Instead, I argue for a decentered collaborative research model which, if adopted, promises to blur the rigid lines between teaching and research institutions. By promoting a culture of disciplined-based pedagogic research, research-led-teaching, teaching-led-research, and inquiry-based learning, this model envisions a symbiotic ecosystem where teaching, learning, and research are intertwined, each enriching the other. It is a clarion call for a systemic reconfiguration that fosters not just interdisciplinary, but interdepartmental and interinstitutional synergies, thereby accelerating the culture of research and scholarship even in primarily undergraduate teaching institutions.
The essence of Open Access dovetails with this vision. It is about engendering a culture of collaborative authorship and open discourse which transcends the traditional institutional silos. It’s about creating avenues for shared resources, collective problem-solving, and communal knowledge building. This collaborative ethos doesn’t just enrich the academic community, but has a rippling effect on the broader societal matrix, by hastening the pace at which innovative solutions to real-world problems are conceived and disseminated.
However, the road to a fully collaborative and open access scholarly ecosystem isn’t without its challenges. For Open Access to flourish and scale, it’s imperative that funding support for researchers is envisaged as a public good. This necessitates a shift in policy frameworks and a reimagining of funding structures to catalyze the rapid and efficient sharing of ideas when they are most pertinent.Furthermore, the collaborative nature of Open Access extends beyond just the academia. It’s about forging partnerships with the wider community, engaging with diverse stakeholders, and creating a robust support infrastructure that facilitates not just the production but the dissemination and utilization of knowledge.
As we celebrate International Open Access Week, it's an opportune moment to reflect on how far we’ve come and the journey that lies ahead. Open Book Publishers, along with the wider Open Access community, is committed to nurturing a collaborative, inclusive, and open knowledge ecosystem. The quintessence of Open Access is not just about access to knowledge, but about fostering a culture of shared inquiry, collective endeavour, and communal growth. Through fostering a collaborative culture, underpinned by open access principles, we are not just accelerating academic innovation, but are taking strides towards a more informed, equitable, and enlightened society.
James Hutson is the author of Gallucci's Commentary on Dürer’s 'Four Books on Human Proportion': Renaissance Proportion Theory, an Open Access title available to read and download for free below
Books on the decorative arts can be expensive to produce and to buy. And they are relatively few, particularly on art pottery. Open Access publishing has served the most immediate community of readers of this book: those who are familiar with, and/or are collectors of Moorcroft's pottery. It has enabled a rapid and international promotion of the book, and downloads from all five continents in the first couple of weeks demonstrate the effectiveness of that process. But it was the ambition of this book to move beyond this (quite limited) community to reach a much broader readership, from those with an interest (either academic or amateur) in pottery more generally or in the material culture of the first half of the twentieth century to those who might enjoy the story of an individual who enjoyed worldwide appreciation in his lifetime, but whose story is being told in detail for the first time. These broader communities are less likely to pay the cover price of a print copy until they know more about the book itself. Open Access publishing has made this much easier to achieve.
To prioritise commercial interest with a book of this kind would have been not to publish it at all. And yet, paradoxically, Open Access is not incompatible with sales. By reaching a wider community of online readers, by putting into the public domain the compelling story of a creative artist responding to turbulent times, together with multiple images of his work never seen before, Open Access publishing allows readers to explore at leisure the detail of the book. And it reaches a much wider community, of whom there will inevitably be some (or many) who may prefer hard copy for more extensive consultation, but who may have been reluctant to buy one sight unseen, or after just cursory inspection in a bookshop. Open Book Publishers' extensive and informed promotional strategies have maximised these opportunities.
But in another, more particular way, publishing William Moorcroft, Potter with OBP has been the perfect match. Moorcroft's work as an artist potter was not motivated by a desire to make money; his ambition was to express himself, and to bring beauty into the lives of others. To that extent, he may be situated in the tradition of William Morris. But whereas many (even most) products of the Arts and Crafts movement were luxury items (for all their appearance of homely simplicity), Moorcroft's pottery was accessible by more than a privileged few. He made expensive wares, collected by connoisseurs of ceramic art, but inexpensive, functional wares, too, affordable by a much broader public. And whatever its size, function or sophistication, it was all made to the same high standards of design and production. As one contemporary critic noted, even his simplest ware is, in the eyes of its owner, a collector's item. Added to which, he was personally very generous with his ware, often giving it away as presents or tokens of gratitude. What mattered to him was that he benefited others, not that he made a profit. Tellingly, he survived the economic pressures of the interwar years more successfully than many of his contemporaries. In more ways than one, he would doubtless have shared the principles of Open Access publishing.
This is an Open Access title available to read and download for free or to purchase in all available print and ebook formats below.
Un plaidoyer du collectif FEMSAM : Élisabeth Arsenault, Marietou Niang, Sophie Dupéré, Marie-Claude Bernard, Isabelle Goupil-Sormany, Valérie Desgroseilliers, Patrice Ngangue et Florence Piron†
Avec la collaboration de la Clinique SPOT, la Coopérative de solidarité SABSA, le Service de référence en périnatalité pour les femmes immigrantes de Québec, Santé Monde et la participation d’Asseita, Fatim, Fatine, Hamscha, Nelly et Malek
Comment les femmes immigrantes de la région de Québec, dont le statut migratoire ne permet pas l’accès au régime d’assurance maladie du Québec, s’organisent-elles pour avoir un accouchement digne, sécuritaire et financièrement accessible? Cette question a mobilisé une équipe de recherche-action participative basée à la Boutique des sciences de l’Université Laval, Accès savoirs, et associée au programme du réseau international Knowledge for Change. Cette recherche a été menée en collaboration avec la Clinique SPOT, une clinique communautaire de santé et d’enseignement, préoccupée par les femmes en situation migratoire précaire ou sans couverture d’assurance maladie, qui sollicitent ses services pendant leur grossesse et leur accouchement. Ce projet a impliqué la participation de six mères et d’un père immigrant·es. Ensemble, nous avons exploré leurs parcours de soins périnataux sans couverture de la RAMQ (Régie de l’assurance maladie du Québec). Ce rapport de recherche se veut un plaidoyer pour le droit à la santé de ces femmes ainsi qu’un réexamen du système d’assurance maladie et de soins, afin qu’il soit plus équitable et inclusif.
Design de la couverture : Kate McDonnell
Date de publication : octobre 2023
***
Table des matières
Introduction
I. État des connaissances
1. Que sait-on de la situation des femmes enceintes immigrantes sans assurance maladie au Québec?
II. Contexte du projet et son approche communautaire participative
2. Contexte et approche des récits de vie
3. Méthode : recrutement et entretiens
4. Les participant·es
III. Nos récits de vie
5. Le récit de Nelly
6. Le récit d’Hamscha
7. Le récit de Fatim
8. Le récit de Fatine
9. Le récit d’Asseita
10. Le récit de Malek
IV. Analyse thématique
11. Analyse thématique transversale
V. Plaidoyer
12. Recommandations des participant·es
13. D’autres recommandations
Références
À propos des Éditions science et bien commun
This series listens to the political, gendered, queer(ed), racial engagements and class entanglements involved in proclaiming out loud: La-TIN-x. ChI-ca-NA. La-TI-ne. ChI-ca-n-@. Xi-can-x. Funded by an Andrew W. Mellon Foundation as part of the Crossing Latinidades Humanities Research Initiative, the Latinx Sound Cultures Studies Working Group critically considers the role of sound and listening in our formation as political subjects. Through both a comparative and cross-regional lens, we invite Latinx Sound Scholars to join us as we dialogue about our place within the larger fields of Chicanx/Latinx Studies and Sound Studies. We are delighted to publish our initial musings with Sounding Out!, a forum that has long prioritized sound from a queered, racial, working-class and “always-from-below” epistemological standpoint. —Ed. Dolores Inés Casillas
—
This post is co-authored by Sara Veronica Hinojos and Eliana Buenrostro
Cardi B eloquently reminds us that our español, as US Latinxs, might seem “muy ratata;” an apt phrase, heard lyrically within her music, used here to characterize inventive, communicative Spanglish word play. Yet, the proliferation of hashtags used to shame and silence second and later generations of Latinx kids runs counter to Cardi B’s ratata blessings.
The hashtags #nosabokid #nosabokids #nosabokidsbelike #nosabokidsorry #iamanosabokid represents a collective acknowledgment of Gloria Anzaldúa’s “linguistic terrorism.” Featured on NBC News, Locatora Radio, the Los Angeles Times and, surely, referenced within familial discussions, #nosabo has brought, once again, to the fore the coupling and, we fiercely argue, the need to decouple language (“proficiency”) from that of Latinx identities. The phrase “no sabo” – a non-standard Spanish conjugation of the phrase “no sé” for “I don’t know” – has become a stand-in as both a linguistic (bad) sign of Americanization and/or a (good) marker of ethnic, bicultural pride.
Anzaldúa has long warned us that, “[e]ven our own people, other Spanish speakers nos quieren poner candados en la boca [want to put locks on our mouths]” (1999, 76). In many ways, the “no sabo” label silences or “locks” one’s mouth. The institutional attempts to Americanize Spanish-speaking individuals constitute a form of violence that has led to the erosion of Spanish spoken among Mexican and Latino families in the United States. Today, children of immigrants are ridiculed for speaking “broken” Spanish, yet, for decades Mexicans raised in the United States experienced harsh consequences and blatant discrimination for speaking Spanish in public; this racism continues today.
As scholars of Latinx listening, these social media posts can be incredibly frustrating. They remind us of the sad reality that many Latinx people do not know their own history or better yet futures. Anzaldúa would describe the intraethnic linguistic policing as, “peleando con nuestra propia sombra” (fighting with our own shadow) (1999, 76); it’s both unproductive and self-inflicting. Poet Michele Serros describes her experiences being policed in her 1993 poem “Mi Problema”:
Applied to speakers (mostly kids) whose Spanish is identified as grammatically wrong or heard with an Anglicized accent, “no sabo” hashtags can encourage people to police each other’s tongues. Social media videos even show parents testing their children’s Spanish. When a child cannot remember or (mis)pronounces a Spanish word, or worse, uses a Spanglish iteration, they are disparagingly called “no sabo kids” (Stransky et al. 2023). Other posts reveal Latinx users’ fear of having and raising a “no sabo kid” or not wanting to date a “no sabo kid.”
Speaking to my kids in Spanish and telling them buenas noches they giggle and say buenos nachossss
Lastly, other posts proudly admit to being a “no sabo kid.” The latest series of “no sabo kids” hashtags are also unapologetic declarations that their language does not define the totality of their being or experiences.
Indeed, speaking Anglicized Spanish as Latinx can surface feelings of embarrassment, disappointment, and mockery from presumed “perfect” Spanish speakers or self-appointed “real” Spanish-English bilinguals. Televised instances of Latin Americans chastising the Spanish spoke of Latinx speakers or the public praise thrown at Ben Affleck for his spoken Spanish in comparison to the public side eyes given to wife, Bronx-raised, Jennifer Lopez are both hyper-mediated instances of #nosabokids.
White people might be praised for learning Spanish – no matter how Anglicized their accent – yet Latinx people whose Spanish is detected as Anglicized, are (racially whitewashed) “no sabo kids” (Urciuoli 2013). And yes, the use of the word “kids” alone infantilizes the speaker as some social media posts point to both children and adults as “no sabo.”
Irrespective of the proficiency in English or Spanish, Latinx individuals share experiences of being corrected in educational settings, at home, or online. The misuse of verb conjugation, such as using “sabo” instead of “sé,” is a developmental challenge encountered even by Spanish-speaking children who are learning solely Spanish. In other words, it is not an exclusive practice among Spanish-English bilingual speakers, despite what social media posts insist. The public discourse that some Latinx social media users are battling is what Jonathan Rosa calls “looking like a language” and, in this case, not “sounding like a race” (Rosa 2019).
imagine i was a no sabo kid & didn’t know what bad bunny was saying
Speaking, listening, and living “muy ratata” with inventive modes of Spanish and English in the U.S. is clearly heard as threatening. For instance, knowledge of another language has always challenged monolingual conservative speakers. Bilingual speakers and listeners routinely teach us how to resignify language practices and ultimately, the meaning of being a “no sabo kid.” (Or how Nancy Morales argues about Los Jornaleros del Norte and Radio Ambulante in the ways they offer new forms of belonging by understanding themselves and respecting each other.)
Entrepreneurs with Chicana and Latina feminist identities are modeling refashioned ways of belonging. For example, Los Angeles-based brand Hija de tu Madre created t-shirts and crewneck sweatshirts with the words “no sabo” to counter the ridicule heard and circulated within social media and to loudly claim a racial, linguistic identity that has nothing to do with shame. Similarly, the card game “Yo Sabo,” founded by a first generation college student of Mexican descent, Carlos Torres, looks for ways to improve his Spanish and simultaneously creates another way to connect with immigrant family members. Labels like “no sabo ” that are intended to categorize people in harmful ways are being repurposed to build community.
The podcast Locatora Radio: A Radiophonic Novela released an episode on April 12, 2023, Capítulo 160: No Sabo Kids, detailing historical reasons why Latinx ethnicities have structurally been banned from learning and speaking Spanish. Perhaps most importantly, Locatora Radio shares with listeners lengthy listener-recorded testimonios.
They provide diverse personal reasons for identifying as a “no sabo kid.” One listener, Paula, is a transracial adoptee whose first language was Spanish. However, because of forced family separation and the foster care system in Virginia, she “lost” her Spanish. Paula was enrolled in Spanish language classes throughout her formal schooling and accepts that her reclaiming of culture and language is a lifelong process. The use of verbal testimonios, a format that makes it possible for podcast listeners to listen to fellow listeners, moves away from posts above that wag their digital finger at “no sabo kids” and instead gives them a space to speak for themselves.
The intense personal and communal fear of losing aspects of culture or language makes it difficult to understand how shifts in language practices and accents are important new forms of belonging as Latinx in the U.S. If we cannot accept our own linguistic diversity, how do we expect others to listen to us?
—
Featured Image: A selection of TikTok #nosabo memes from @marlene.ramir, @yospanishofficial, and @saianana
—
Sara Veronica Hinojos is an Assistant Professor of Media Studies at Queens College, CUNY. Her research focuses on representation of Chicanx and Latinx within popular film and television with an emphasis on gender, race, language politics, and humor studies. She is currently working on a book manuscript that investigates the racial function of linguistic “accents” within media, called: GWAT?!: Chicanx Mediated Race, Gender, and “Accents” in the US.
Eliana Buenrostro is a Ph.D. student at the University of California, Riverside in the Department of Ethnic Studies. She received her master’s in Latin American and Latino Studies from the University of Illinois at Chicago. Her research examines the criminalization, immigration, and deportation of Chicanes and Latines through the lens of music and other forms of cultural production. She is a recipient of the Crossing Latinidades Mellon Fellowship.
This series listens to the political, gendered, queer(ed), racial engagements and class entanglements involved in proclaiming out loud: La-TIN-x. ChI-ca-NA. La-TI-ne. ChI-ca-n-@. Xi-can-x. Funded by an Andrew W. Mellon Foundation as part of the Crossing Latinidades Humanities Research Initiative, the Latinx Sound Cultures Studies Working Group critically considers the role of sound and listening in our formation as political subjects. Through both a comparative and cross-regional lens, we invite Latinx Sound Scholars to join us as we dialogue about our place within the larger fields of Chicanx/Latinx Studies and Sound Studies. We are delighted to publish our initial musings with Sounding Out!, a forum that has long prioritized sound from a queered, racial, working-class and “always-from-below” epistemological standpoint. —Ed. Dolores Inés Casillas
—
This post is co-authored by Sara Veronica Hinojos and Eliana Buenrostro
Cardi B eloquently reminds us that our español, as US Latinxs, might seem “muy ratata;” an apt phrase, heard lyrically within her music, used here to characterize inventive, communicative Spanglish word play. Yet, the proliferation of hashtags used to shame and silence second and later generations of Latinx kids runs counter to Cardi B’s ratata blessings.
The hashtags #nosabokid #nosabokids #nosabokidsbelike #nosabokidsorry #iamanosabokid represents a collective acknowledgment of Gloria Anzaldúa’s “linguistic terrorism.” Featured on NBC News, Locatora Radio, the Los Angeles Times and, surely, referenced within familial discussions, #nosabo has brought, once again, to the fore the coupling and, we fiercely argue, the need to decouple language (“proficiency”) from that of Latinx identities. The phrase “no sabo” – a non-standard Spanish conjugation of the phrase “no sé” for “I don’t know” – has become a stand-in as both a linguistic (bad) sign of Americanization and/or a (good) marker of ethnic, bicultural pride.
Anzaldúa has long warned us that, “[e]ven our own people, other Spanish speakers nos quieren poner candados en la boca [want to put locks on our mouths]” (1999, 76). In many ways, the “no sabo” label silences or “locks” one’s mouth. The institutional attempts to Americanize Spanish-speaking individuals constitute a form of violence that has led to the erosion of Spanish spoken among Mexican and Latino families in the United States. Today, children of immigrants are ridiculed for speaking “broken” Spanish, yet, for decades Mexicans raised in the United States experienced harsh consequences and blatant discrimination for speaking Spanish in public; this racism continues today.
As scholars of Latinx listening, these social media posts can be incredibly frustrating. They remind us of the sad reality that many Latinx people do not know their own history or better yet futures. Anzaldúa would describe the intraethnic linguistic policing as, “peleando con nuestra propia sombra” (fighting with our own shadow) (1999, 76); it’s both unproductive and self-inflicting. Poet Michele Serros describes her experiences being policed in her 1993 poem “Mi Problema”:
Applied to speakers (mostly kids) whose Spanish is identified as grammatically wrong or heard with an Anglicized accent, “no sabo” hashtags can encourage people to police each other’s tongues. Social media videos even show parents testing their children’s Spanish. When a child cannot remember or (mis)pronounces a Spanish word, or worse, uses a Spanglish iteration, they are disparagingly called “no sabo kids” (Stransky et al. 2023). Other posts reveal Latinx users’ fear of having and raising a “no sabo kid” or not wanting to date a “no sabo kid.”
Speaking to my kids in Spanish and telling them buenas noches they giggle and say buenos nachossss
Lastly, other posts proudly admit to being a “no sabo kid.” The latest series of “no sabo kids” hashtags are also unapologetic declarations that their language does not define the totality of their being or experiences.
Indeed, speaking Anglicized Spanish as Latinx can surface feelings of embarrassment, disappointment, and mockery from presumed “perfect” Spanish speakers or self-appointed “real” Spanish-English bilinguals. Televised instances of Latin Americans chastising the Spanish spoke of Latinx speakers or the public praise thrown at Ben Affleck for his spoken Spanish in comparison to the public side eyes given to wife, Bronx-raised, Jennifer Lopez are both hyper-mediated instances of #nosabokids.
White people might be praised for learning Spanish – no matter how Anglicized their accent – yet Latinx people whose Spanish is detected as Anglicized, are (racially whitewashed) “no sabo kids” (Urciuoli 2013). And yes, the use of the word “kids” alone infantilizes the speaker as some social media posts point to both children and adults as “no sabo.”
Irrespective of the proficiency in English or Spanish, Latinx individuals share experiences of being corrected in educational settings, at home, or online. The misuse of verb conjugation, such as using “sabo” instead of “sé,” is a developmental challenge encountered even by Spanish-speaking children who are learning solely Spanish. In other words, it is not an exclusive practice among Spanish-English bilingual speakers, despite what social media posts insist. The public discourse that some Latinx social media users are battling is what Jonathan Rosa calls “looking like a language” and, in this case, not “sounding like a race” (Rosa 2019).
imagine i was a no sabo kid & didn’t know what bad bunny was saying
Speaking, listening, and living “muy ratata” with inventive modes of Spanish and English in the U.S. is clearly heard as threatening. For instance, knowledge of another language has always challenged monolingual conservative speakers. Bilingual speakers and listeners routinely teach us how to resignify language practices and ultimately, the meaning of being a “no sabo kid.” (Or how Nancy Morales argues about Los Jornaleros del Norte and Radio Ambulante in the ways they offer new forms of belonging by understanding themselves and respecting each other.)
Entrepreneurs with Chicana and Latina feminist identities are modeling refashioned ways of belonging. For example, Los Angeles-based brand Hija de tu Madre created t-shirts and crewneck sweatshirts with the words “no sabo” to counter the ridicule heard and circulated within social media and to loudly claim a racial, linguistic identity that has nothing to do with shame. Similarly, the card game “Yo Sabo,” founded by a first generation college student of Mexican descent, Carlos Torres, looks for ways to improve his Spanish and simultaneously creates another way to connect with immigrant family members. Labels like “no sabo ” that are intended to categorize people in harmful ways are being repurposed to build community.
The podcast Locatora Radio: A Radiophonic Novela released an episode on April 12, 2023, Capítulo 160: No Sabo Kids, detailing historical reasons why Latinx ethnicities have structurally been banned from learning and speaking Spanish. Perhaps most importantly, Locatora Radio shares with listeners lengthy listener-recorded testimonios.
They provide diverse personal reasons for identifying as a “no sabo kid.” One listener, Paula, is a transracial adoptee whose first language was Spanish. However, because of forced family separation and the foster care system in Virginia, she “lost” her Spanish. Paula was enrolled in Spanish language classes throughout her formal schooling and accepts that her reclaiming of culture and language is a lifelong process. The use of verbal testimonios, a format that makes it possible for podcast listeners to listen to fellow listeners, moves away from posts above that wag their digital finger at “no sabo kids” and instead gives them a space to speak for themselves.
The intense personal and communal fear of losing aspects of culture or language makes it difficult to understand how shifts in language practices and accents are important new forms of belonging as Latinx in the U.S. If we cannot accept our own linguistic diversity, how do we expect others to listen to us?
—
Featured Image: A selection of TikTok #nosabo memes from @marlene.ramir, @yospanishofficial, and @saianana
—
Sara Veronica Hinojos is an Assistant Professor of Media Studies at Queens College, CUNY. Her research focuses on representation of Chicanx and Latinx within popular film and television with an emphasis on gender, race, language politics, and humor studies. She is currently working on a book manuscript that investigates the racial function of linguistic “accents” within media, called: GWAT?!: Chicanx Mediated Race, Gender, and “Accents” in the US.
Eliana Buenrostro is a Ph.D. student at the University of California, Riverside in the Department of Ethnic Studies. She received her master’s in Latin American and Latino Studies from the University of Illinois at Chicago. Her research examines the criminalization, immigration, and deportation of Chicanes and Latines through the lens of music and other forms of cultural production. She is a recipient of the Crossing Latinidades Mellon Fellowship.
On 3 May 1979, the Conservative Party under Margaret Thatcher won the UK General Election. Thatcher and her supplicants did not subscribe to the post-war British consensus, the bargain made with the returning troops of World War Two and the population that had stood unbroken as the home front that there was to be mass housebuilding for municipal rent, a National Health Service and the Welfare State.
So those concessions began to be reversed through the Thatcher government’s Chicago School economics in the form of ‘monetarism’, actually a strategy to shrink the state. The mass unemployment it caused threatened her downfall but the Falklands War gave Thatcher her second victory. And then in March 1984 came the Miners’ Strike.
As Francis Beckett and David Hencke have put it, ‘Britain before the great miners’ strike of 1984-5 and Britain after it are two fundamentally different places, and they have little in common.’(i) The transition from a country with institutions predicated on diminishing inequality and injustice, on universal health care and an end to poverty, to that of today in which homelessness is growing and the NHS dies a slow death by ten thousand cuts, where the life expectancy of certain social groups is decreasing and the gap between the rich and the poor ever growing, begins here.
The Miners’ Strike was a showdown Thatcher and her allies had been planning since long before coming to power, an act of revenge for the miners’ two-fold defeat and eventual removal of Ted Heath’s Tory government of 1970-74. Its prosecution began with the publication of a list of mines to be closed in the British coalfields, where the pit was often also the focus of community and social organisation. So this was not just an attack on an industry but on all the aspects of ways of life. Along with stringent anti-trade union laws, the unstated aim was to inaugurate the systematic removal of the labour movement as a political force in the UK state.
The strike would last for a year during which the leaders of that labour movement would fail to substantively support the miners’ struggle, but among the grass roots of the Labour Party and the trades unions the support for the miners was intense. As Seumas Milne notes:
Throughout the dispute of 1984–5, in the face of a wall of hostile propaganda and nightly scenes of violence played out on television, rarely less than a third of the adult population–representing around 15 million people–supported the NUM and the strike: a strike for jobs and the defence of mining communities, but also a strike for social solidarity and a different kind of Britain. (ii)
Four people in Cornwall were amongst those who felt a burning need to support the strike. What they had in common was experience in theatre so they decided to express their support through performance. This was the birth of A39 Theatre Group. To create the work, we drew on the heritage of agitprop. Other resources were the plays and writings of John McGrath and Bertolt Brecht. Our roots were in our shared socialism and the counterculture of the 1960s and 70s.
Though the strike was defeated we continued our work to disseminate its arguments in Cornish communities through our play One & All!, a social history of Cornwall’s own mining of tin and copper from her granite hillsides. Soon we discovered that the defence and strengthening of Cornish communities was to fight for the same causes as those of the Miners’ Strike.
One of the stories told by my book After the Miners’ Strike is of a theatre company that was a contemporaneous expression of resistance to that transition to the place the UK has become under Thatcher and her legacy. If you want to understand now, you really need to understand then.
(i) Beckett, Francis and David Hencke, ‘Preface’, in Marching to the Fault Line: The Miners’ Strike and the Battle for Industrial Britain (London: Constable, 2009).
(ii) Seumas Milne, The Enemy Within: The Secret War Against the Miners (London: Verso 2014) p. 352.
This is an Open Access title available to read and download for free or to purchase in all available print and ebook formats below.
***This post is co-written by Petra Rivera-Rideau andVanessa Díaz
On the night of September 12, Colombian pop star Shakira made history as the first predominantly Spanish-language artist to be honored as MTV’s Video Vanguard at the Video Music Awards (VMAs). The award recognizes artists who have had a major and innovative impact on music videos and popular music. Shakira played a 10-minute medley of Spanish and English hits from her three-decades long career. Her performance demonstrated her breadth as an artist as she shifted from pop to rock to reggaetón.
Not only did she demonstrate her impressive musical range, but of her 69 singles, Shakira selected those that represent two significant crossover moments for Latin music. She sang hits like “Wherever, Whenever,” “Hips Don’t Lie,” and “She Wolf” from her English-language crossover in the early 2000s as part of the so-called “Latin Boom.” She sang 2001’s “Objection (Tango)” with the same samba/rock music arrangement she used at her very first VMA performance in 2002.
During this “Latin Boom” of the late 1990s and early 2000s, Shakira and other established Latin stars who had previously performed in Spanish, such as Ricky Martin, Marc Anthony, and the late Selena Quintanilla, dominated the charts with English-language albums. Despite their successful global careers in the Latin market—and the long history and influence of Latinx musicians in U.S. pop music–U.S. media consistently portrayed these artists as exotic newcomers to the scene, praised more for being “Latin lovers” than established musicians. The Latin boom stars were valued as spicy foreigners there to expose Americans to new, exotic Latin sounds – conga beats, flamenco-style guitar riffs, and festive horns – even as many of these songs draw from familiar rock/pop references. Draco Rosa, one Ricky Martin’s co-writers, remembers “channeling [Jim] Morrison” and “elements of big band … a little bit of surf guitar” in the 1999 smash “Livin’ La Vida Loca.”
Despite the Latin Boom’s English-language crossovers, the images and sounds associated with the moment underscored the artists’ foreignness, something that continues today. This year’s Grammys’ botched treatment of superstar Bad Bunny’s performance and acceptance speech, in which, in lieu of translations, the subtitles merely declared that his words were “non-English.” Spanish has long been used to signify Latinxs’ alleged foreignness and inability to assimilate into US life and culture despite the fact that Latinx communities have been part of the fabric of the US for centuries. In the context of increased anti-immigrant sentiment, the popularity of Spanish-speaking artists like Bad Bunny and Shakira takes on even greater significance.
Following the Grammy’s disastrous handling of Bad Bunny’s performance and speech, backlash ensued. A plethora of popular memes and even t-shirts proudly claiming non-English popped up almost overnight. New York Times’ critic and Princeton professor Yarimar Bonilla proclaimed that “Bad Bunny is [Winning in Non-English].” Celebrities from comedian Cristela Alonzo to rapper 50 Cent admonished CBS. Even California Congressman Robert Garcia sent a letter directly to the CBS president and CEO George Cheeks, writing that the incident “display[ed] a lack of sensitivity and foresight. For too many Spanish-speaking Americans, it felt disrespectful of our place in our shared society, and of our contributions to our shared culture.” CBS eventually released a tepid statement saying that their vendor was not adequately equipped to manage Benito’s Spanish-language speech and performance, and Cheeks took “full responsibility” for the incident. Overall, the Grammys snafu reflects the ways in which the American mainstream still is incapable of embracing the status of Latin artists as equal players in the US and global music markets, in any language.
Compared to this year’s Grammys, however, MTV’s VMAs offered a much more inclusive approach, with a historic perspective that demonstrated exactly how we were able to arrive at this new moment in Latin music. When Puerto Rican and Cuban American rapper Fat Joe and Mexican pop star Thalia presented the award for Best Latin video, Thalia reminded the audience that “in the 2000s’ first Latin explosion, we had a song together, and now we’re here celebrating again this new Latin explosion.” This new Latin explosion refers to the numerous Spanish-language artists like Shakira, Bad Bunny, Karol G, and Peso Pluma who have recently broken out in the US mainstream.
But, unlike the previous Latin Boom, these artists have maintained their Spanish and their musical style. Bad Bunny’s Grammy performance included plena, reggaeton, and merengue rather than the kitschy styles of his Latin Boom predecessors. In addition to selling out stadiums around the country, Karol G drew 15,000 fans, the largest crowd in the Today Show’s history, for her reggaetón performance as part of the program’s Summer Concert Series in Rockefeller Center. Just this past September, Eslabon Armado became the first Mexican regional music group to ever perform on Good Morning America with their chart-topping hit “Ella Baila Sola” (the first Mexican regional song to ever hit number one on Billboard’s Global 200 chart). Whether it is the percussive dembow beat of reggaetón or the syncopated horns of corridos tumbados, all of these musicians have maintained the sounds of their respective genres, foregoing the stereotypical “Latin” sonic signifiers historically associated with Latin music.
Shakira herself reflected this moment in her Video Vanguard performance. She performed her new Spanish-language songs as 2022’s “Te Felicito,” and 2023’s “TQG” and “Bzrp Music Sessions: Volume 53” (the latter having broken four Guinness world records, including the most streamed Latin track in 24 hours). All of these songs have been part of this new Latin music movement. In fact, her “TQG” collaborator Karol G also performed her Spanish hits at the show. Mexican regional phenom Peso Pluma sang “Lady Gaga” on a small stage, surrounded only by his band, and called out “¡arriba México!” at the end. Brazilian artist Anitta performed a multilingual medley from her Funk Generation: A Favela Love Story. In addition, Shakira and Karol G won the award for best collaboration for “TQG.” Not only did the women give their acceptance speech in Spanish, shouting out their home country of Colombia, but they also won in a category otherwise populated by mainstream English-language artists like Doja Cat with Post Malone, and Metro Boomin with The Weeknd, 21 Savage, and Diddy. The interchangeable, tropical Latinidad of the earlier Latin boom was replaced with shout outs to specific countries and regions, and the crowd proudly waved Mexican, Puerto Rican, and Colombian flags. At the VMAs, Latin musicians were not isolated in Latin awards categories or depicted as exotic novelties. They were central to the show – nominated for major awards, and celebrated for some of the night’s most memorable performances.
Much like this year’s Coachella, which featured Bad Bunny and K-Pop sensation Black Pink as headliners, this year’s VMAs reflects a more global approach to pop music. Tuesday night’s award show also featured two performances by K-Pop groups, and MTV offered its first ever award in Best Afrobeats. In this context, it makes sense that Latin music would have a significant presence in the program. But the dominance of Latin music right now makes it so that no part of the music industry can leave Latin music out anymore. Not the VMAs, not the Grammys, not Coachella. As Thalia proudly declared on stage, “this last year for the first time in the US Latin music made a billion dollars in streaming.” Bad Bunny has been the most streamed artist on Spotify for three years in a row, has the longest-running Spanish-language album at the top of the Billboard chart, and in 2022 became the only artist in history to stage two separate $100 million-grossing tours in less than 12 months. Karol G became the first woman to have a Spanish-language debut at number one, and came to the VMAs after a string of historic performances at her Mañana Será Bonito stadium tour. Latin music’s global appeal is undeniable and the industry has to respond accordingly.
This is among the most important times in history for Latin music, and honoring artists like Shakira center stage at the VMAs helps underscore the musical evolution we are lucky enough to witness. Twenty years ago, Shakira had to crossover into the US market in English; now she performs in her native Spanish and is more relevant than ever. The global success of stars like Peso Pluma, Karol G, and Bad Bunny means we need to completely reevaluate the concept of the crossover. Latin artists today did not crossover, the market crossed over into them. They are not compromising their language, their identity, or their culture. They do not have to kowtow to industry expectations that they perform the exotic, sexy Latin other. So while the VMA Vanguard Award winner Shakira may have had to crossover into English to make it during the ‘90s Latin boom, she can proudly return to her roots and, this time, the market will follow her.
—
Featured Image: Screen shot by SO! from Shakira’s MTV 2023 Video Vanguard acceptance speech
—
Petra Rivera-Rideau is Associate Professor of American Studies at Wellesley College, and the author of Remixing Reggaetón: The Cultural Politics of Race in Puerto Rico and the forthcoming book Fun, Fitness, Fiesta: Selling Latinx Culture in Zumba Fitness. Vanessa Díaz is Associate Professor of Chicana/o and Latina/o Studies at Loyola Marymount University, and the author of Manufacturing Celebrity: Latino Paparazzi and Women Reporters in Hollywood. Díaz and Rivera-Rideau are the co-creators of the Bad Bunny Syllabus.






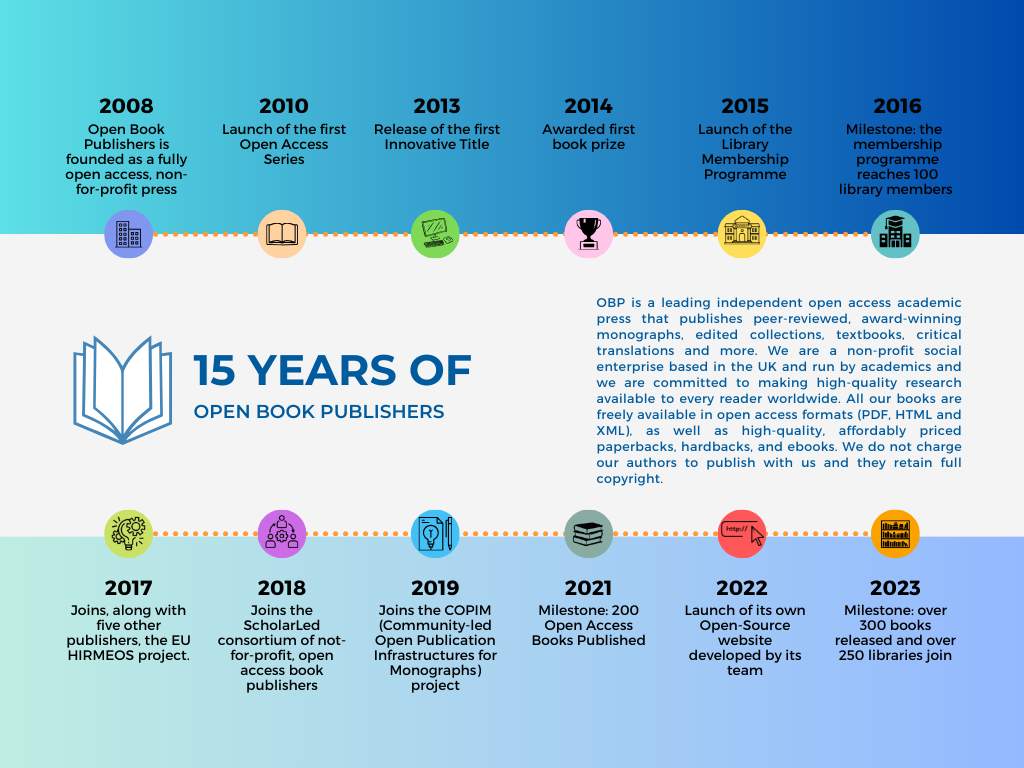










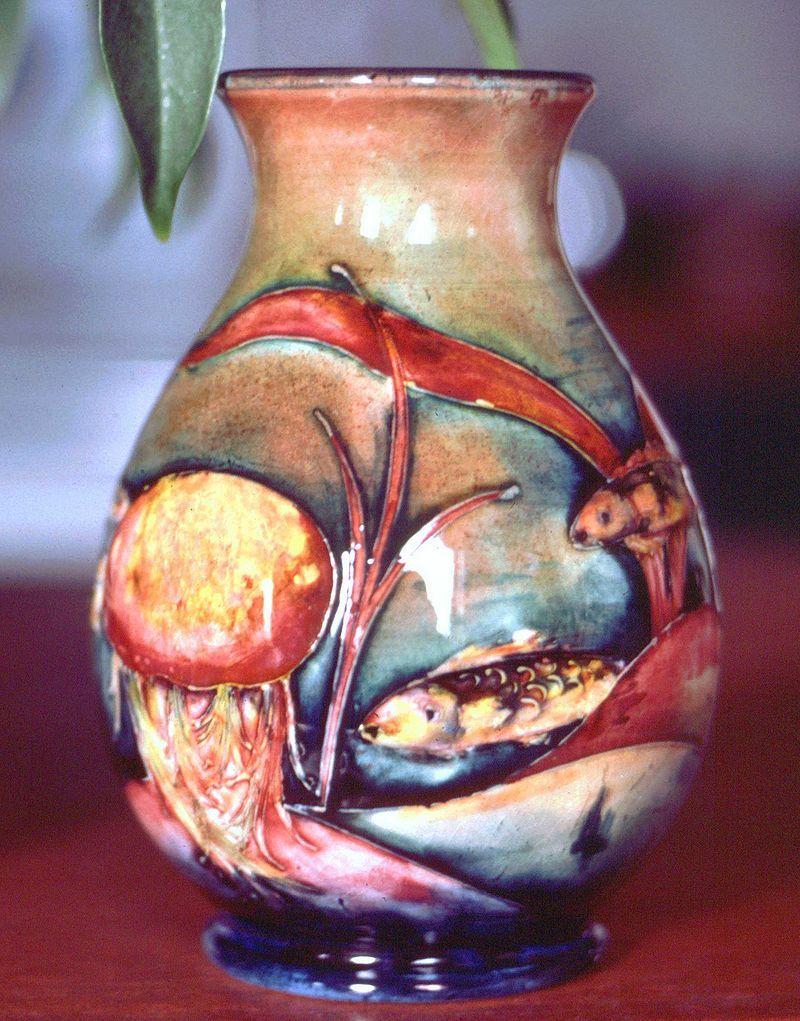



 I’m not tryna have some no sabo kids
I’m not tryna have some no sabo kids 𝖁𝖊𝖊
𝖁𝖊𝖊  (@miblogestublog)
(@miblogestublog)  M
M

 (@SimplySelena101)
(@SimplySelena101)  (@miblogestublog)
(@miblogestublog) 

